看完本文后:妈妈再也不用担心我不知道InnoDB是怎么加锁的了!
一个错误的观点
在使用加锁读的方式读取使用InnoDB存储引擎的表时,当在执行查询时没有使用到索引时,行锁会被转换为表锁。
这里强调一点,对于任何INSERT、DELETE、UP
DATE、SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE语句来说,InnoDB存储引擎都不会加表级别的S锁或者X锁,只会加行级锁。所以即使对于全表扫描的加锁读语句来说,也只会对表中的记录进行加锁,而不是直接加一个表锁。
锁到底是什么
锁是一个内存结构,InnoDB中用lock_t这个结构来定义:
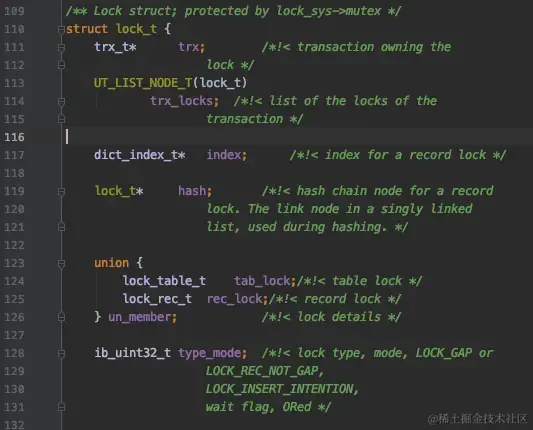
不论是行锁,还是表锁都用这个结构来表示。
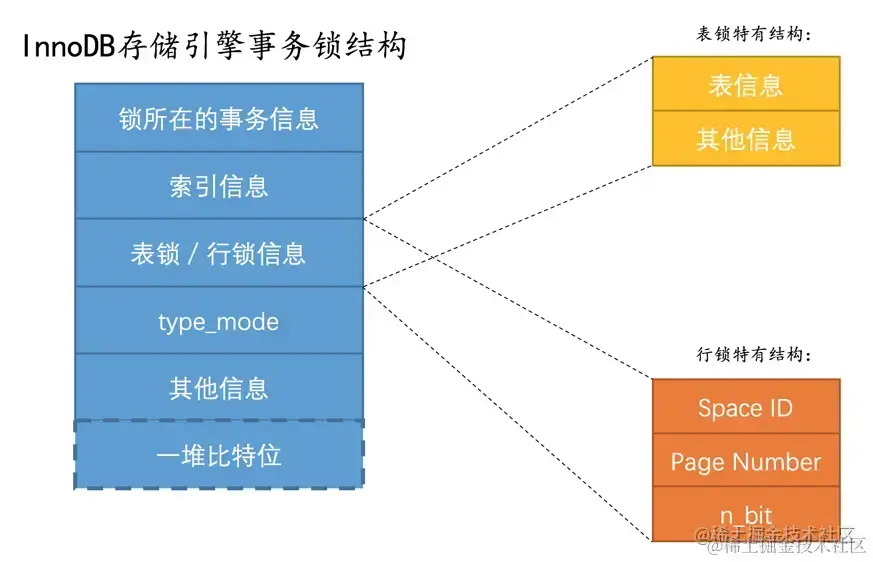
其中的type_mode是用于区分这个锁结构到底是行锁还是表锁,如果是表锁的话是意向锁、直接对表加锁、还是AUTO-INC锁,如果是行锁的话,具体是正经记录锁、gap锁还是next-key锁。
在InnoDB的实现中,InnoDB的行锁是与记录一一对应的。即使是对于gap锁来说,在实现上也是为某条记录生成一个锁结构,然后该锁结构的类型是gap锁而已,并不是专门为某个区间生成一个锁结构。该gap锁的功能就是每当有别的事务插入记录时,会检查一下待插入记录的下一条记录上是否已经有一个gap锁的锁结构,如果有的话就进入阻塞状态。
加锁受哪些因素影响
一条语句加什么锁受多种因素影响,如果你不能确认下边这些因素的时候,最好不要抢先发言说”XXX语句对XXX记录加了什么锁”:
- 事务的隔离级别
- 语句执行时使用的索引类型
- 是否精确匹配
- 是否唯一性匹配
- 具体执行的语句类型
- 是否开启innodb_locks_unsafe_for_binlog系统变量
- 记录是否被标记删除
事前准备
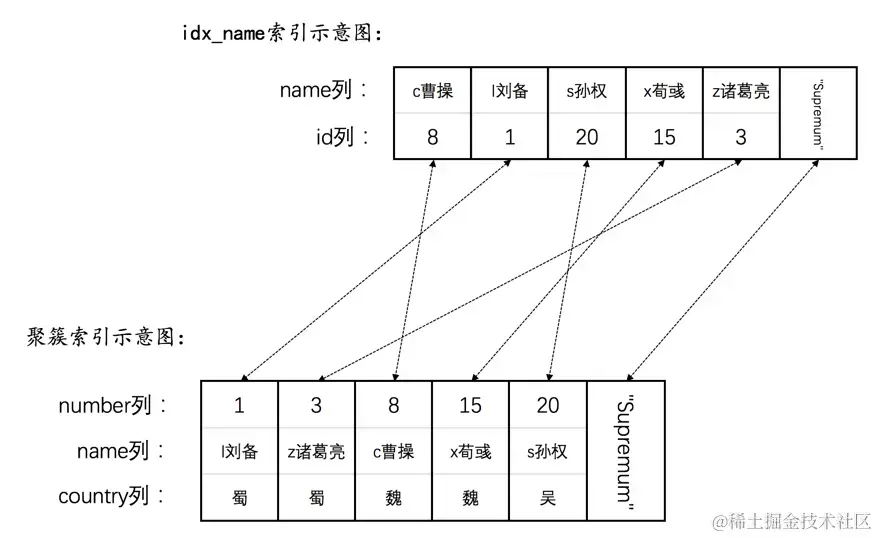
建立一个存储三国英雄的hero表:
CREATE TABLE hero (
number INT,
name VARCHAR(100),
country varchar(100),
PRIMARY KEY (number),
KEY idx_name (name)
) Engine=InnoDB CHARSET=utf8;
INSERT INTO hero VALUES
(1, 'l刘备', '蜀'),
(3, 'z诸葛亮', '蜀'),
(8, 'c曹操', '魏'),
(15, 'x荀彧', '魏'),
(20, 's孙权', '吴');
ALTER TABLE hero ADD INDEX idx_name (name);
然后现在hero表就有了两个索引(一个二级索引,一个聚簇索引),示意图如下:
锁定读的语句
我们把下边四种语句放到一起讨论:
- 语句一:
SELECT ... LOCK IN SHARE MODE; - 语句二:
SELECT ... FOR UPDATE; - 语句三:
UPDATE ... - 语句四:
DELETE ...
我们说语句一和语句二是MySQL中规定的两种锁定读的语法格式,而语句三和语句四由于在执行过程需要首先定位到被改动的记录并给记录加锁,也可以被认为是一种锁定读。
READ COMMITTED隔离级别下
对于使用主键进行等值查询的情况
- 使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:
SELECT * FROM hero WHERE number = 8 LOCK IN SHARE MODE;
这个语句执行时只需要访问一下聚簇索引中number值为8的记录,所以只需要给它加一个S型正经记录锁就好了
- 使用
UPDATE ...来为记录加锁,比方说:
UPDATE hero SET country = '汉' WHERE number = 8;
这条UPDATE语句并没有更新二级索引列,加锁方式和上边所说的SELECT ... FOR UPDATE语句一致。
如果UPDATE语句中更新了二级索引列,比方说:
UPDATE hero SET name = 'cao曹操' WHERE number = 8;
该语句的实际执行步骤是首先更新对应的number值为8的聚簇索引记录,再更新对应的二级索引记录,所以加锁的步骤就是:
- 为
number值为8的聚簇索引记录加上X型正经记录锁(该记录对应的)。 - 为该聚簇索引记录对应的
idx_name二级索引记录(也就是name值为'c曹操',number值为8的那条二级索引记录)加上X型正经记录锁。
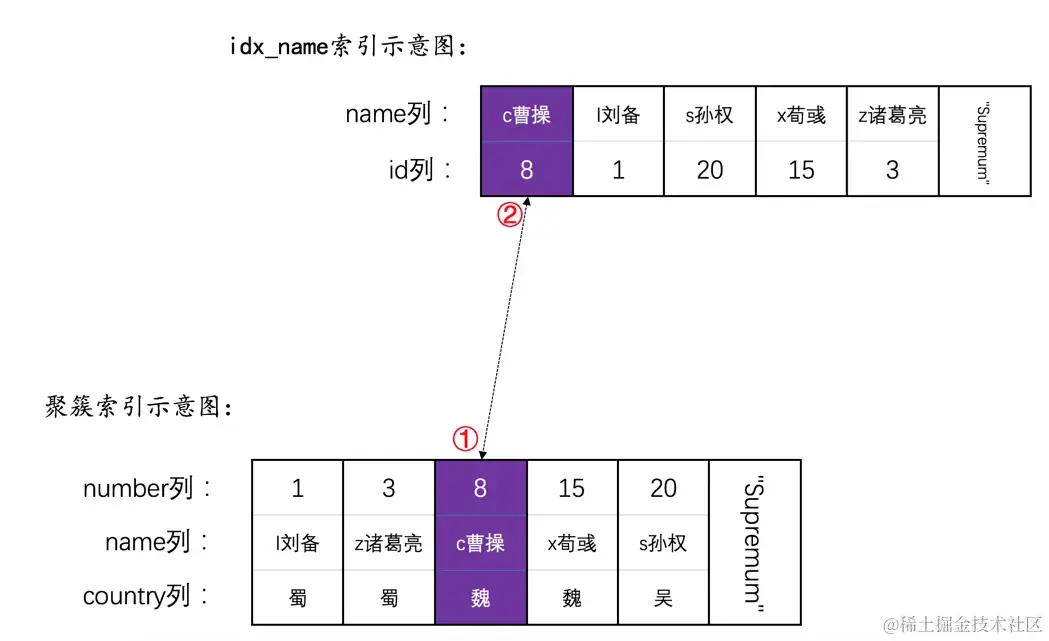
我们用带圆圈的数字来表示为各条记录加锁的顺序。
- 使用
DELETE ...来为记录加锁,比方说:
DELETE FROM hero WHERE number = 8;
我们平时所说的“DELETE表中的一条记录”其实意味着对聚簇索引和所有的二级索引中对应的记录做DELETE操作,本例子中就是要先把number值为8的聚簇索引记录执行DELETE操作,然后把对应的idx_name二级索引记录删除,所以加锁的步骤和上边更新带有二级索引列的UPDATE语句一致
对于使用主键进行范围查询的情况
- 使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:
SELECT * FROM hero WHERE number <= 8 LOCK IN SHARE MODE;
这条语句的执行流程看起来比较简单,但实际执行还是比较复杂的:
先到聚簇索引中定位到满足
number <= 8的第一条记录,也就是number值为1的记录,然后为其加锁。判断一下该记录是否符合
索引条件下推中的条件。索引条件下推(Index Condition Pushdown,简称ICP)的功能,也就是把查询中与被使用索引有关的查询条件下推到存储引擎中判断,而不是返回到server层再判断。不过需要注意的是,
索引条件下推只是为了减少回表次数,也就是减少读取完整的聚簇索引记录的次数,从而减少IO操作。而对于聚簇索引而言不需要回表,它本身就包含着全部的列,也起不到减少IO操作的作用,所以设计InnoDB的大叔们规定这个索引条件下推特性只适用于二级索引。也就是说在本例中与被使用索引有关的条件是:number <= 8,而number列又是聚簇索引列,所以本例中并没有符合索引条件下推的查询条件,自然也就不需要判断该记录是否符合索引条件下推中的条件。判断一下该记录是否符合范围查询的边界条件
因为在本例中是利用主键number进行范围查询,设计InnoDB的大叔规定每从聚簇索引中取出一条记录时都要判断一下该记录是否符合范围查询的边界条件,也就是number <= 8这个条件。如果符合的话将其返回给server层继续处理,否则的话需要释放掉在该记录上加的锁,并给server层返回一个查询完毕的信息。
- 将该记录返回到
server层继续判断。
server层如果收到存储引擎层提供的查询完毕的信息,就结束查询,否则继续判断那些没有进行索引条件下推的条件,在本例中就是继续判断number <= 8这个条件是否成立。这不是在第3步已经判断过了吗?怎么还要判断一次!?
InnoDB设计的策略是:把凡是没有经过
索引条件下推的条件都需要放到server层再判断一遍。如果该记录符合剩余的条件(没有进行索引条件下推的条件),那么就把它发送给客户端,不然的话需要释放掉在该记录上加的锁。
- 然后刚刚查询得到的这条记录(也就是
number值为1的记录)组成的单向链表继续向后查找,得到了number值为3的记录,然后重复第2,3,4、5这几个步骤。
上述步骤是在MySQL 5.7.21这个版本中验证的,不保证其他版本有无出入。
但在查询过程中也会出现问题,就是当找到number值为8的那条记录的时候,还得向后找一条记录(也就是number值为15的记录),在存储引擎读取这条记录的时候,也就是上述的第1步中,就得为这条记录加锁,然后在第3步时,判断该记录不符合number <= 8这个条件,又要释放掉这条记录的锁,这个过程导致number值为15的记录先被加锁,然后把锁释放掉,过程就是这样:
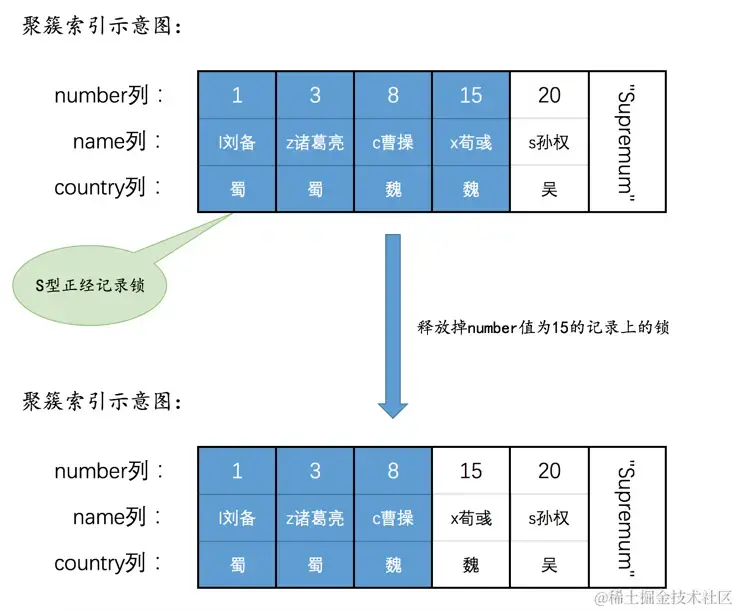
再看一个使用主键进行范围查询的例子:
SELECT * FROM hero WHERE number >= 8 LOCK IN SHARE MODE;
这条语句也是首先在聚簇索引中定位满足number >= 8这个条件的第一条记录,也就是number值为8的记录,然后就可以沿着由记录组成的单向链表一路向后找,每找到一条记录,就会为其加上锁,然后判断该记录符不符合范围查询的边界条件,不过这里的边界条件比较特殊:number >= 8,只要记录不小于8就算符合边界条件,所以判断和没判断是一样一样的。
最后把这条记录返回给server层,server层再判断number >= 8这个条件是否成立,如果成立的话就发送给客户端,否则的话就结束查询。
不过InnoDB存储引擎找到索引中的最后一条记录,也就是Supremum伪记录之后,在存储引擎内部就可以立即判断这是一条伪记录,不必要返回给server层处理,也没必要给它也加上锁(也就是说在第1步中就压根儿没给这条记录加锁)。
使用
SELECT ... FOR UPDATE语句来为记录加锁:和
SELECT ... LOCK IN SHARE MODE语句类似,只不过加的是X型正经记录锁。使用
UPDATE ...来为记录加锁
如果UPDATE语句并没有更新二级索引列,加锁方式和上边所说的SELECT ... FOR UPDATE语句一致。
如果UPDATE语句中更新了二级索引列,比方说:
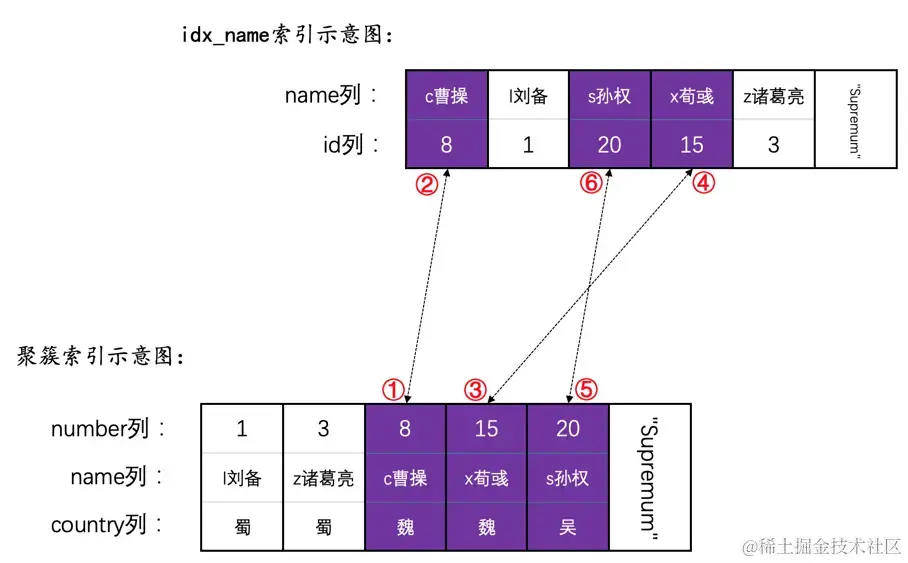
UPDATE hero SET name = 'cao曹操' WHERE number >= 8;
这时候会首先更新聚簇索引记录,再更新对应的二级索引记录,所以加锁的步骤如图所示:
对于使用二级索引进行等值查询的情况
- 使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:
SELECT * FROM hero WHERE name = 'c曹操' LOCK IN SHARE MODE;
这个语句的执行过程是先通过二级索引idx_name定位到满足name = 'c曹操'条件的二级索引记录,然后进行回表操作。所以先要对二级索引记录加S型正经记录锁,然后再给对应的聚簇索引记录加S型正经记录锁
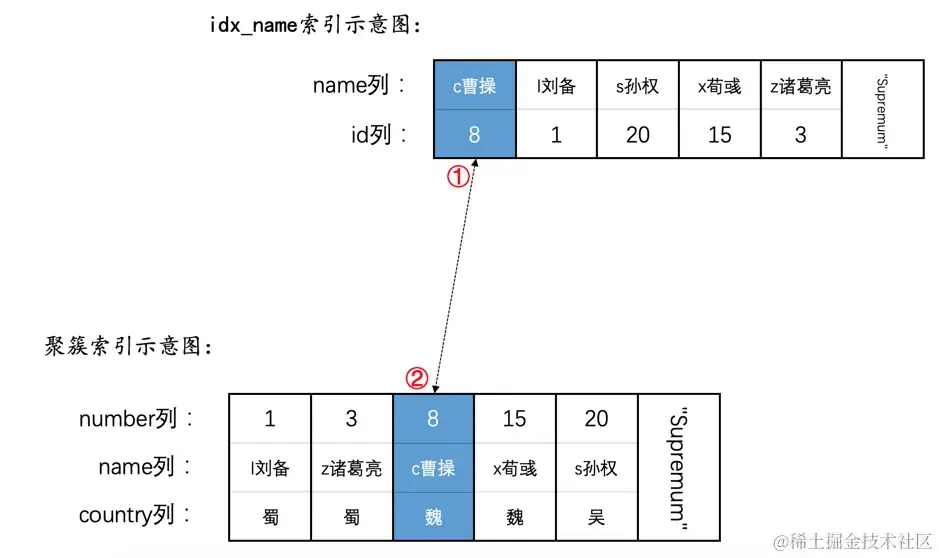
这里需要再次强调一下这个语句的加锁顺序:
- 先对
name列为'c曹操'二级索引记录进行加锁。 - 再对相应的聚簇索引记录进行加锁。
小贴士:
我们知道idx_name是一个普通的二级索引,到idx_name索引中定位到满足name= ‘c曹操’这个条件的第一条记录后,就可以沿着这条记录一路向后找。可是从我们上边的描述中可以看出来,并没有对下一条二级索引记录进行加锁,这是为什么呢?
这是因为设计InnoDB的大叔对等值匹配的条件有特殊处理,他们规定在InnoDB存储引擎层查找到当前记录的下一条记录时,在对其加锁前就直接判断该记录是否满足等值匹配的条件,如果不满足直接返回(也就是不加锁了),否则的话需要将其加锁后再返回给server层。所以这里也就不需要对下一条二级索引记录进行加锁了。
- 使用
SELECT ... FOR UPDATE语句时,比如:
SELECT * FROM hero WHERE name = 'c曹操' FOR UPDATE;
这种情况下与SELECT ... LOCK IN SHARE MODE语句的加锁情况类似,都是给访问到的二级索引记录和对应的聚簇索引记录加锁,只不过加的是X型正经记录锁罢了。
- 使用
UPDATE ...来为记录加锁,比方说:
与更新二级索引记录的SELECT ... FOR UPDATE的加锁情况类似,不过如果被更新的列中还有别的二级索引列的话,对应的二级索引记录也会被加锁。
- 使用
DELETE ...来为记录加锁,比方说:
与SELECT ... FOR UPDATE的加锁情况类似,不过如果表中还有别的二级索引列的话,对应的二级索引记录也会被加锁。
对于使用二级索引进行范围查询的情况
- 使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:
SELECT * FROM hero FORCE INDEX(idx_name) WHERE name >= 'c曹操' LOCK IN SHARE MODE;
这个语句的执行过程其实是先到二级索引中定位到满足name >= 'c曹操'的第一条记录,也就是name值为c曹操的记录,然后就可以沿着这条记录的链表一路向后找,从二级索引idx_name的示意图中可以看出,所有的用户记录都满足name >= 'c曹操'的这个条件,所以所有的二级索引记录都会被加S型正经记录锁,它们对应的聚簇索引记录也会被加S型正经记录锁。
不过需要注意一下加锁顺序,对一条二级索引记录加锁完后,会接着对它相应的聚簇索引记录加锁,完后才会对下一条二级索引记录进行加锁,以此类推~
再来看下边这个语句:
SELECT * FROM hero FORCE INDEX(idx_name) WHERE name <= 'c曹操' LOCK IN SHARE MODE;
前边说在使用number <= 8这个条件的语句中,需要把number值为15的记录也加一个锁,之后又判断它不符合边界条件而把锁释放掉。而对于查询条件name <= 'c曹操'的语句来说,执行该语句需要使用到二级索引,而与二级索引相关的条件是可以使用索引条件下推这个特性的。
设计InnoDB的大叔规定,如果一条记录不符合索引条件下推中的条件的话,直接跳到下一条记录(这个过程根本不将其返回到server层),如果这已经是最后一条记录,那么直接向server层报告查询完毕。
但是这里头有个问题呀:先对一条记录加了锁,然后再判断该记录是不是符合索引条件下推的条件,如果不符合直接跳到下一条记录或者直接向server层报告查询完毕,这个过程中**并没有把那条被加锁的记录上的锁释放掉**呀!!!。
本例中使用的查询条件是name <= 'c曹操',在为name值为'c曹操'的二级索引记录以及它对应的聚簇索引加锁之后,会接着二级索引中的下一条记录,也就是name值为'l刘备'的那条二级索引记录,由于该记录不符合索引条件下推的条件,而且是范围查询的最后一条记录,会直接向server层报告查询完毕,重点是这个过程中并不会释放name值为'l刘备'的二级索引记录上的锁,也就导致了语句执行完毕时的加锁情况如下所示:
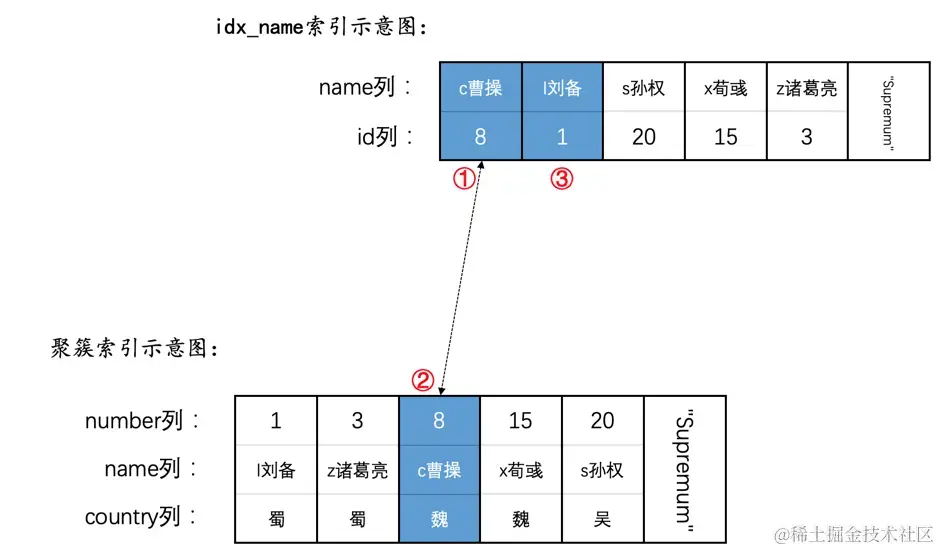
使用
SELECT ... FOR UPDATE语句时:和
SELECT ... FOR UPDATE语句类似,只不过加的是X型正经记录锁。使用
UPDATE ...来为记录加锁,比方说:
UPDATE hero SET country = '汉' WHERE name >= 'c曹操';
FORCE INDEX只对SELECT语句起作用,UPDATE语句虽然支持该语法,但实质上不起作用,DELETE语句压根儿不支持该语法。
假设该语句执行时使用了idx_name二级索引来进行锁定读,那么它的加锁方式和上边所说的SELECT ... FOR UPDATE语句一致。如果有其他二级索引列也被更新,那么也会为对应的二级索引记录进行加锁,就不赘述了。不过还有一个有趣的情况,比方说:
UPDATE hero SET country = '汉' WHERE name <= 'c曹操';
我们前边说的索引条件下推这个特性只适用于SELECT语句,也就是说UPDATE语句中无法使用,那么这个语句就会为name值为'c曹操'和'l刘备'的二级索引记录以及它们对应的聚簇索引进行加锁,之后在判断边界条件时发现name值为'l刘备'的二级索引记录不符合name <= 'c曹操'条件,再把该二级索引记录和对应的聚簇索引记录上的锁释放掉。这个过程如下图所示:
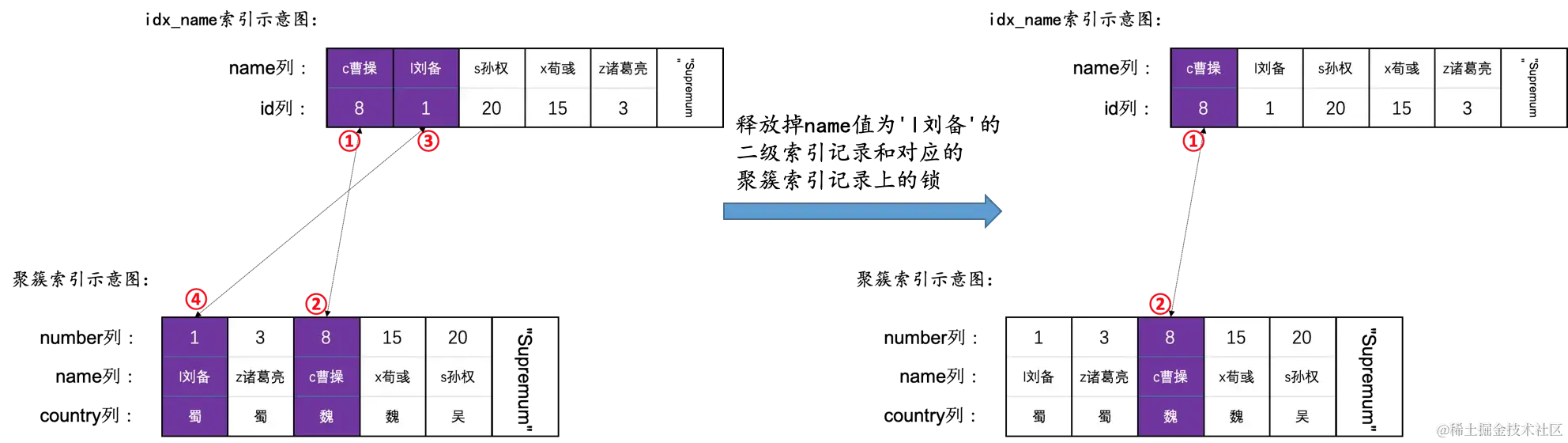
- 使用
DELETE ...来为记录加锁,比方说:
DELETE FROM hero WHERE name >= 'c曹操';
如果语句采用二级索引来进行锁定读,那么它们的加锁情况和更新带有二级索引列的UPDATE语句一致,就不画图了。
全表扫描的情况
SELECT * FROM hero WHERE country = '魏' LOCK IN SHARE MODE;
由于country列上未建索引,所以只能采用全表扫描的方式来执行这条查询语句,存储引擎每读取一条聚簇索引记录,就会为这条记录加锁一个S型正常记录锁,然后返回给server层,如果server层判断country = '魏'这个条件是否成立,如果成立则将其发送给客户端,否则会释放掉该记录上的锁
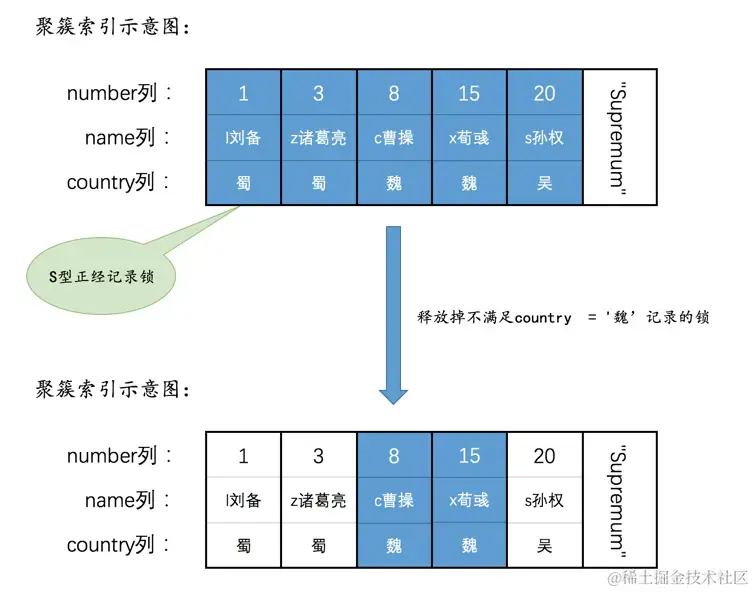
使用SELECT ... FOR UPDATE进行加锁的情况与上边类似,只不过加的是X型正经记录锁,就不赘述了。
对于UPDATE ...和DELETE ...的语句来说,在遍历聚簇索引中的记录,都会为该聚簇索引记录加上X型正经记录锁,然后:
- 如果该聚簇索引记录不满足条件,直接把该记录上的锁释放掉。
- 如果该聚簇索引记录满足条件,则会对相应的二级索引记录加上
X型正经记录锁(DELETE语句会对所有二级索引列加锁,UPDATE语句只会为更新的二级索引列对应的二级索引记录加锁)。
文档信息
- 本文作者:L1Chenxv
- 本文链接:https://l1chenxv.github.io//2025/03/09/mysql-lock-process/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)