事务有ACID四个核心属性:
A:原子性。事务要么不执行,要么完全执行。如果执行到一半,宕机重启,已执行的⼀半要回滚回去。
C:一致性。各种约束条件,比如主键不能为空、参照完整性等。
I:隔离性。隔离性和并发性密切相关,因为如果事务全是串行的(第四个隔离级别),也不需要隔离。
D:持久性。这个很容易理解,⼀旦事务提交了,数据就不能丢。
在这四个属性中,D比较容易,C主要是由上层的各种规则来约束,也相对简单。而A和I牵涉并发问题、崩溃恢复的问题,将是讨论的重点。
接下来,就以InnoDB为背景,分析事务的ACID其中的三个属性(A、I、D)是如何实现的。先从最简单的D开始(I/O问题),然后是A,最后讨论I。
由于篇幅问题,本节只讨论日志如何保证事务特性,至于锁如何实现事务特性,请小伙伴耐心等待之后的文章~
事务实现原理之1:Redo Log
1. Write-Ahead
Write-ahead Log的思路:先在内存中提交事务,然后写⽇志(所谓的Write-ahead Log),然后后台任务把内存中的数据异步刷到磁盘。⽇志是顺序地在尾部Append,从⽽也就避免了⼀个事务发⽣多次磁盘随机 I/O 的问题。明明是先在内存中提交事务,后写的⽇志,为什么叫作Write-Ahead呢?
这⾥的Ahead,其实是指相对于真正的数据刷到磁盘,因为是先写的⽇志,后把内存数据刷到磁盘,所以叫Write-Ahead Log。
内存操作数据+Write-Ahead Log的这种思想非常普遍,后⾯讲LSM树的时候,还会再次提到这个思想。在多备份⼀致性中,复制状态机的模型也是基于此。
2. Redo Log 的逻辑与物理结构
知道了Redo Log的基本设计思想,下⾯来看Redo Log的详细结构。
从逻辑上来讲,⽇志就是⼀个⽆限延长的字节流,从数据库安装好并启动的时间点开始,⽇志便源源不断地追加,永⽆结束。
但从物理上来讲,⽇志不可能是⼀个永不结束的字节流,⽇志的物理结构和逻辑结构,有两个⾮常显著的差异点:
(1) 磁盘的读取和写⼊都不是按⼀个个字节来处理的,磁盘是“块”设备,为了保证磁盘的I/O效率,都是整块地读取和写⼊。对于RedoLog来说,就是Redo Log Block,每个Redo Log Block是512字节。为什么是512字节呢?因为早期的磁盘,⼀个扇区(最细粒度的磁盘存储单位)就是存储512字节数据。
(2) ⽇志⽂件不可能⽆限制膨胀,过了⼀定时期,之前的历史⽇志就不需要了,通俗地讲叫“归档”,专业术语是Checkpoint。所以Redo Log 其实是⼀个固定⼤⼩的⽂件,循环使⽤,写到尾部之后,回到头部覆写(实际Redo Log是⼀组⽂件,但这⾥就当成⼀个⼤⽂件,不影响对原理的理解)。之所以能覆写,因为⼀旦 Page 数据刷到磁盘上,⽇志数据就没有存在的必要了。
下图展示了Redo Log逻辑与物理结构的差异,LSN(Log Sequence Number)是逻辑上日志按照时间顺序从小到大的编号。在InnoDB中,LSN是一个64位的整数,取的是从数据库安装启动开始,到当前所写入的总的日志字节数。实际上LSN没有从0开始,而是从8192开始,这个是InnoDB源代码里面的一个常量LOG_START_LSN。因为事务有大有小,每个事务产生的日志数据量是不一样的,所以日志是变长记录,因此LSN是单调递增的,但肯定不是呈单调连续递增。
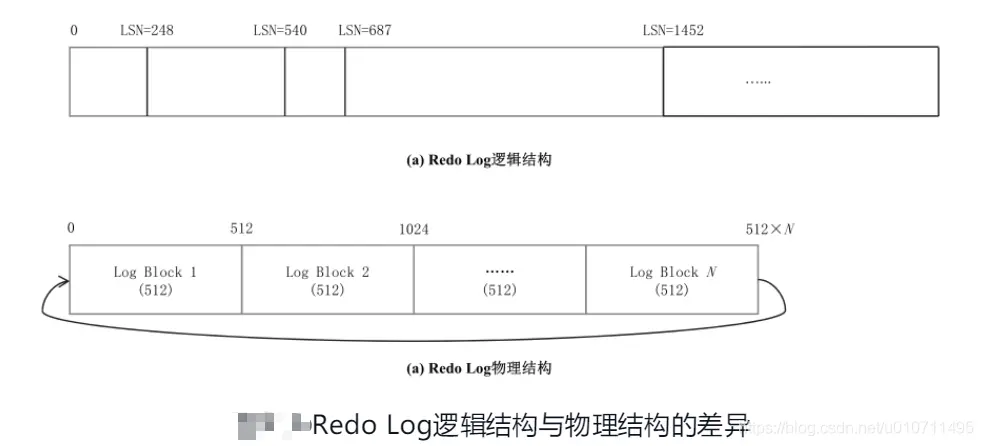
物理上面,一个固定的文件大小,每 512 个字节一个 Block,循环使用。显然,很容易通过LSN换算出所属的Block。反过来,给定Redo Log,也很容易算出第一条日志在什么位置。假设在Redo Log中,从头到尾所记录的LSN依次如下所示:(200,289,378,478,30,46,58,69,129) 很显然,第1条日志是30,最后1条日志是478,30以前的已经被覆盖。
3. Physiological Logging
知道了Redo Log的整体结构,下⾯进⼀步来看每个Log Block⾥⾯Log的存储格式。这个问题很关键,是数据库事务实现的⼀个核⼼点。
(1)记法1。类似Binlog的statement格式,记原始的SQL语句,insert/delete/update。
(2)记法2。类似Binlog的RAW格式,记录每张表的每条记录的修改前的值、修改后的值,类似(表,行,修改前的值,修改后的值)。
(3)记法3。记录修改的每个Page的字节数据。由于每个Page有16KB,记录这16KB里哪些部分被修改了。一个Page如果被修改了多个地方,就会有多条物理日志,如下所示:
(Page ID,offset1,len1,改之前的值,改之后的值) (Page ID,offset2,len2,改之前的值,改之后的值)
前两种记法都是逻辑记法;第三种是物理记法。
Redo Log采用了哪种记法呢?它采用了逻辑和物理的综合体,就是先以Page为单位记录日志,每个Page里面再采取逻辑记法(记录Page里面的哪一行被修改了)。这种记法有个专业术语,叫Physiological Logging。要搞清楚为什么要采用Physiological Logging,就得知道逻辑日志和物理日志的对应关系:
(1)一条逻辑日志可能产生多个Page的物理日志。比如往某个表中插入一条记录,逻辑上是一条日志,但物理上可能会操作两个以上的Page?为什么呢,因为一个表可能有多个索引,每个索引都是一颗B+树,插入一条记录,同时更新多个索引,自然可能修改多个Page。如果Redo Log采用逻辑日志的记法,一条记录牵涉的多个Page写到一半系统宕机了,要恢复的时候很难知道到底哪个Page写成功了,哪个失败了。
(2)即使1条逻辑日志只对应一个Page,也可能要修改这个Page的多个地方。因为一个Page里面的记录是用链表串联的,所以如果在中间插入一条记录,不仅要插入数据,还要修改记录前后的链表指针。对应到Page就是多个位置要修改,会产生多条物理日志。
所以纯粹的逻辑日志宕机后不好恢复;物理日志又太大,一条逻辑日志就可能对应多条物理日志。Physiological Logging综合了两种记法的优点,先以Page为单位记录日志,在每个Page里面再采用逻辑记法
举个例子,一种作用于Page类型的REDOLOG中记录了对Page中一个Record的修改,方法如下:
(Page ID,Record Offset,(Filed 1, Value 1) … (Filed i, Value i) … )
其中,PageID指定要操作的Page页,Record Offset记录了Record在Page内的偏移位置,后面的Field数组,记录了需要修改的Field以及修改后的Value。
Redo Log 记录内容
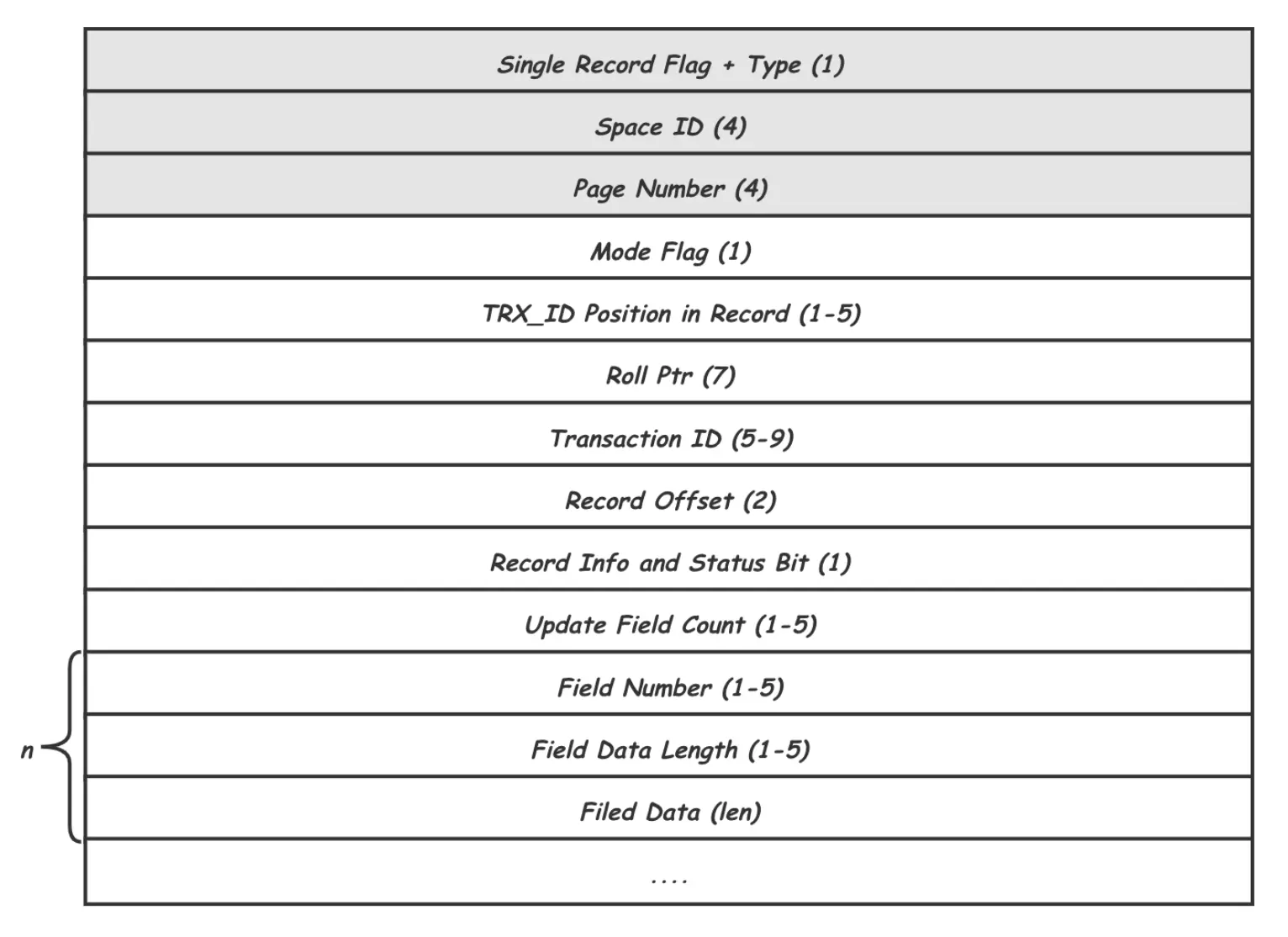
其中Type就是记录的作用对象(根据REDO记录不同的作用对象,可划分为三个大类:作用于Page,作用于Space以及提供额外信息的Logic类型),Space ID和Page Number唯一标识一个Page页,这三项是所有REDO记录都需要有的头信息。
后面的是MLOG_REC_UPDATE_IN_PLACE类型(作用于Page)独有的,其中Record Offset用给出要修改的记录在Page中的位置偏移,Update Field Count说明记录里有几个Field要修改,紧接着对每个Field给出了Field编号(Field Number),数据长度(Field Data Length)以及数据(Filed Data)
4. I/O写入的原子性(Double Write)
要实现事务的原⼦性,先得考虑磁盘I/O的原⼦性。⼀个Log Block是512个字节。假设调⽤操作系统的⼀次Write,往磁盘上写⼊⼀个LogBlock(512个字节),如果写到⼀半机器宕机后再重启,请问写⼊成功的字节数是0,还是[0,512]之间的任意⼀个数值?
这个问题的答案并不唯⼀,可能与操作系统底层和磁盘的机制有关,
如果底层实现了 512个字节写⼊的原⼦性,上层就不需要做什么事情;否则,在上层就需要考虑这个问题。假设底层没有保证512个字节的原⼦性,可以通过在⽇志中加⼊checksum解决。通过checksum能判断出宕机之后重启,⼀个Log Block是否完整。如果不完整,就可以丢弃这个LogBlock,对⽇志来说,就是做截断操作。
除了⽇志写⼊有原⼦性问题,数据写⼊的原⼦性问题更⼤。⼀个Page有16KB,往磁盘上刷盘,如果刷到⼀半系统宕机再重启,请问这个 Page是什么状态?在这种情况下,Page 既不是⼀个脏的Page,也不是⼀个⼲净的Page,⽽是⼀个损坏的Page。既然已经有Redo Log了,不能⽤Redo Log恢复这个Page吗?
因为Redo Log也恢复不了。因为Redo Log是Physiological Logging,⾥⾯只是⼀个对Page的修改的逻辑记录,Redo Log记录了哪个地⽅修改了,但不知道哪个地⽅损坏了。另外,即使为这个Page加了checksum,也只能判断出Page损坏了,只能丢弃,但⽆法恢复数据。有两个解决办法:
(1)让硬件⽀持16KB写⼊的原⼦性。要么写⼊0个字节,要么16KB全部成功。
(2)Double write。把16KB写⼊到⼀个临时的磁盘位置,写⼊成功后再拷贝到⽬标磁盘位置。
5. 事务、LSN与Log Block的关系
下⾯从⼀个事务的提交开始分析,看事务和对应的Redo Log之间的关联关系。假设有⼀个事务,伪代码如下:
start transaction
update 表1某行记录
delete 表1某行记录
insert 表2某行记录
commit
其产生的日志,如图6-10所示。应用层所说的事务都是“逻辑事务”,具体到底层实现,是“物理事务”,也叫作Mini Transaction(Mtr)。在逻辑层面,事务是三条SQL语句,涉及两张表;在物理层面,可能是修改了两个Page(当然也可能是四个Page,五个Page……),每个Page的修改对应一个Mtr。每个Mtr产生一部分日志,生成一个LSN。
这个“逻辑事务”产生了两段日志和两个LSN。分别存储到Redo Log的Block里,这两段日志可能是连续的,也可能是不连续的(中间插入的有其他事务的日志)。所以,在实际磁盘上面,一个逻辑事务对应的日志不是连续的,但一个物理事务(Mtr)对应的日志一定是连续的(即使横跨多个Block)。
下图展示了两个逻辑事务,其对应的Redo Log在磁盘上的排列示意图。可以看到,LSN是单调递增的,但是两个事务对应的日志是交叉排列的。
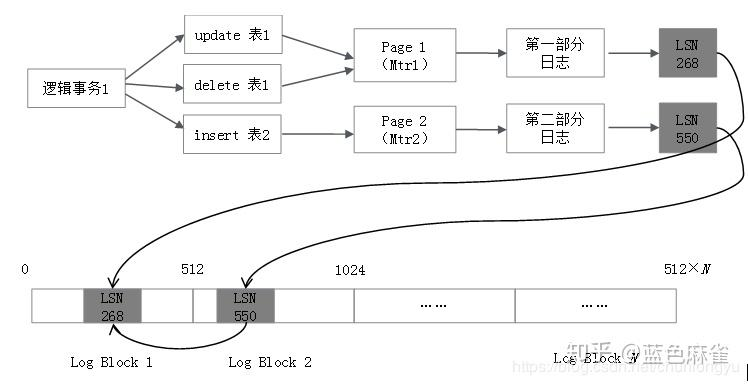
事务与产生的Redo Log对应关系
6. 事务Rollback与崩溃恢复(ARIES算法)
1.未提交事务的日志也在Redo Log中
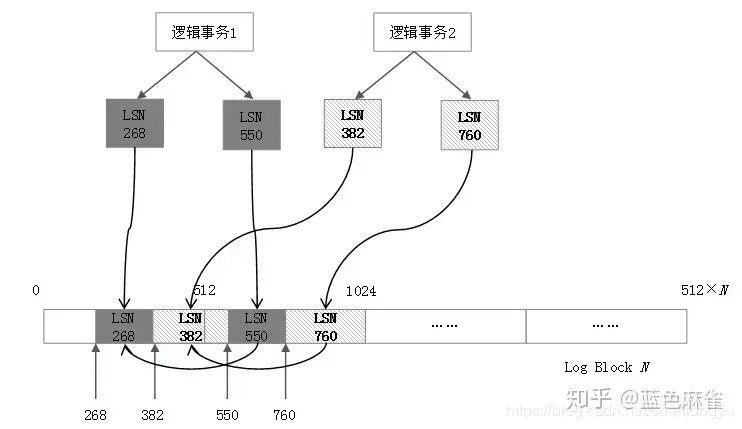
通过上面的分析,可以看到不同事务的日志在Redo Log中是交叉存在的,这意味着未提交的事务也在Redo Log中!因为日志是交叉存在的,没有办法把已提交事务的日志和未提交事务的日志分开,或者说前者刷到磁盘的Redo Log上面,后者不刷。比如图6-11的场景,逻辑事务1提交了,要把逻辑事务1的Redo Log刷到磁盘上,但中间夹杂的有逻辑事务2的部分Redo Log,逻辑事务2此时还没有提交,但其日志会被“连带”地刷到磁盘上。
所以这是ARIES算法的一个关键点,不管事务有没有提交,其日志都会被记录到Redo Log上。当崩溃后再恢复的时候,会把Redo Log全部重放一遍,提交的事务和未提交的事务,都被重放了,从而让数据库“原封不动”地回到宕机之前的状态,这叫Repeating History。
重放完成后,再把宕机之前未完成的事务找出来。这就有个问题,怎么把宕机之前未完成的事务全部找出来?这点讲Checkpoint时会详细介绍。 把未完成的事务找出来后,逐一利用Undo Log回滚。
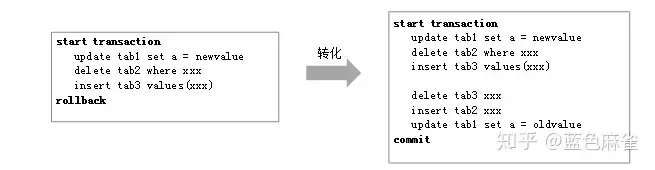
2.Rollback转化为Commit 回滚是把未提交事务的Redo Log删了吗?显然不是。在这里用了一个巧妙的转化方法,把回滚转化成为提交。
如图所示,客户端提交了Rollback,数据库并没有更改之前的数据,而是以相反的方向生成了三个新的SQL语句,然后Commit,所以是逻辑层面上的回滚,而不是物理层面的回滚。
同样,如果宕机时一个事务执行了一半,在重启、回滚的时候,也并不是删除之前的部分,而是以相反的操作把这个事务“补齐”,然后Commit
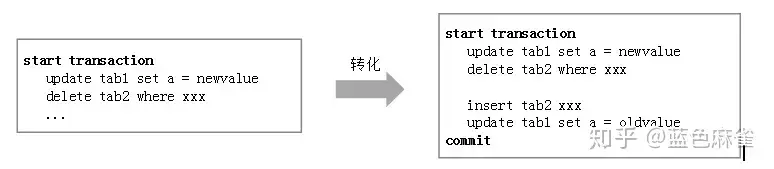
这样一来,事务的回滚就变得简单了,不需要改之前的数据,也不需要改Redo Log。相当于没有了回滚,全部都是Commit。对于Redo Log来说,就是不断地append。这种逆向操作的SQL语句对应到Redo Log里面,叫作Compensation Log Record(CLR),会和正常操作的SQL的Log区分开。
3.ARIES恢复算法
如图6-14所示,有T0~T5共6个事务,每个事务所在的线段代表了在Redo Log中的起始和终止位置。发生宕机时,T0、T1、T2已经完成,T3、T4、T5还在进行中,所以回滚的时候,要回滚T3、T4、T5。
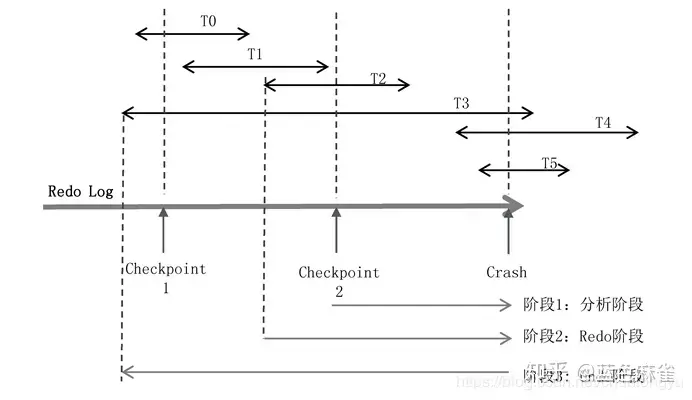
ARIES算法分为三个阶段:
(1)阶段1:分析阶段 分析阶段,要解决两个核心问题。
第一,确定哪些数据页是脏页,为阶段2的Redo做准备。发生宕机时,虽然T0、T1、T2已经提交了,但只是Redo Log在磁盘上,其对应的数据Page是否已经刷到磁盘上不得而知。如何找出从Checkpoint到Crash之前,所有未刷盘的Page呢?
第二,确定哪些事务未提交,为阶段3的Undo做准备。未提交事务的日志也写入了Redo Log。对应到此图,就是T3、T4、T5的部分日志也在Redo Log中。如何判断出T3、T4、T5未提交,然后对其回滚呢?
这就要谈到ARIES的Checkpoint机制。Checkpoint是每隔一段时间对内存中的数据拍一个“快照”,或者说把内存中的数据“一次性”地刷到磁盘上去。但实际上这做不到!因为在把内存中所有的脏页往磁盘上刷的时候,数据库还在不断地接受客户端的请求,这些脏页一直在更新。除非把系统阻塞住,不再接受前端的请求,这时Redo Log也不再增长,然后一次性把所有的脏页刷到磁盘中,叫作Sharp Checkpoint。
Sharp Checkpoint的应用场景很狭窄,因为系统不可能停下来,所以用的更多的是Fuzzy Checkpoint,具体怎么做呢?
在内存中,维护了两个关键的表:活跃事务表和脏页表。 活跃事务表是当前所有未提交事务的集合,每个事务维护了一个关键变量lastLSN,是该事务产生的日志中最后一条日志的LSN。
脏页表是当前所有未刷到磁盘上的Page的集合(包括了已提交的事务和未提交的事务),recoveryLSN是导致该Page为脏页的最早的LSN。比如一个Page本来是clean的(内存和磁盘上数据一致),然后事务1修改了它,对应的LSN是LSN1;之后事务2、事务3又修改了它,对应的LSN分别是LSN2、LSN3,这里recoveryLSN取的就是LSN1。
*所谓的Fuzzy Checkpoint,就是对这两个关键表做了一个Checkpoint,而不是对数据本身做Checkpoint。这点非常巧妙!因为Page本身很多、数据量大,但这两个表记录的全是ID,数据量很小,很容易备份。*
所以,每一次Fuzzy Checkpoint,就把两个表的数据生成一个快照,形成一条Checkpoint日志,记入Redo Log。
基于这两个关键表,可以求取两个问题:
问题(1):求取Crash的时候,未提交事务的集合。
以图6-14为例,在最近的一次Checkpoint 2时候,未提交事务集合是{T2,T3},此时还没有T4、T5。从此处开始,遍历Redo Log到末尾。 在遍历的过程中,首先遇到了T2的结束标识,把T2从集合中移除,剩下{T3}; 之后遇到了事务T4的开始标识,把T4加入集合,集合变为{T3,T4}; 之后遇到了事务T5的开始标识,把T5加入集合,集合变为{T3,T4,T5}。 最终直到末尾,没有遇到{T3,T4,T5}的结束标识,所以未提交事务是{T3,T4,T5}。
图6-15展示了事务的开始标识、结束标识以及Checkpoint在Redo Log中的排列位置。其中的S表示Start transaction,事务开始的日志记录;C表示Commit,事务结束的日志记录。每隔一段时间,做一次Checkpoint,会插入一条Checkpoint日志。Checkpoint日志记录了Checkpoint时所对应的活跃事务的列表和脏页列表(脏页列表在图中未展示)。
问题(2):求取Crash的时候,所有未刷盘的脏页集合。
假设在Checkpoint2的时候,脏页的集合是{P1,P2}。从Checkpoint开始,一直遍历到Redo Log末尾,一旦遇到Redo Log操作的是新的Page,就把它加入脏页集合,最终结果可能是{P1,P2,P3,P4}。
这里有个关键点:从Checkpoint2到Crash,这个集合会只增不减。可能P1、P2在Checkpoint之后已经不是脏页了,但把它认为是脏页也没关系,因为Redo Log是幂等的。
阶段2:进行Redo
假设最后求出来的脏页集合是{P1,P2,P3,P4,P5}。在这个集合中,可能都是真的脏页,也可能是已经刷盘了。取集合中所有脏页的recoveryLSN的最小值,得到firstLSN。从firstLSN遍历Redo Log到末尾,把每条Redo Log对应的Page全部重刷一次磁盘。
关键是如何做幂等?磁盘上的每个Page有一个关键字段——pageLSN。这个LSN记录的是这个Page刷盘时最后一次修改它的日志对应的LSN。如果重放日志的时候,日志的LSN <= pageLSN,则不修改日志对应的Page,略过此条日志。
例如,Page1被多个事务先后修改了三次,在Redo Log的时间线上,分别对应的日志的LSN为600、900、1000。当前在内存中,Page1的pageLSN = 1000(最新的值),因为还没来得及刷盘,所以磁盘中Page1的pageLSN = 900(上一次的值)。现在,宕机重启,从LSN=600的地方开始重放,从磁盘上读出来pageLSN = 900,所以前两条日志会直接过滤掉,只有LSN = 1000的这条日志对应的修改操作,会被作用到Page1中。
这点与TCP在接收端对数据包的判重有异曲同工之妙!在TCP中,是对发送的数据包从小到大编号(seq number),这里是对所有日志从小到大编号(LSN),接收的一方发现收到的日志编号比之前的还要小,就说明不用重做了。
有了这种判重机制,我们就实现了Redo Log重放时的幂等。从而可以从firstLSN开始,将所有日志全部重放一遍,这里面包含了已提交事务和未提交事务的日志,也包含对应的脏页或者干净的页。
Redo完成后,就保证了所有的脏页都成功地写入到了磁盘,干净页也可能重新写入了一次。并且未提交事务T3、T4、T5对应的Page数据也写入了磁盘。接下来,就是要对T3、T4、T5回滚。
阶段3:进行Undo
在阶段1,我们已经找出了未提交事务集合{T3,T4,T5}。从最后一条日志逆向遍历,因为每条日志都有一个prevLSN字段,所以可以沿着T3、T4、T5各自的日志链一直回溯,最终直到T3的第一条日志。
所谓的Undo,是指每遇到一条属于T3、T4、T5的Log,就生成一条逆向的SQL语句来执行,其执行对应的Redo Log是Compensation Log Record(CLR),会在Redo Log尾部继续追加。所以对于Redo Log来说,其实不存在所谓的“回滚”,全部是正向的Commit,日志只会追加,不会执行“物理截断”之类的操作。
要生成逆向的SQL语句,需要记录对应的历史版本数据,这点将在分析Undo Log的时候详细解释。
这里要注意的是:Redo的起点位置和Undo的起点位置并没有必然的先后关系,图中画的是Undo的起点位置小于Redo的起点位置,但实际也可以反过来。以为Redo对应的是所有脏页的最小LSN,Undo对应的是所有未提交事务的起始LSN,两者不是同一个维度的概念。 在进行Undo操作的时候,还可能会遇到一个问题,回滚到一半,宕机,重启,再回滚,要进行“回滚的回滚”。
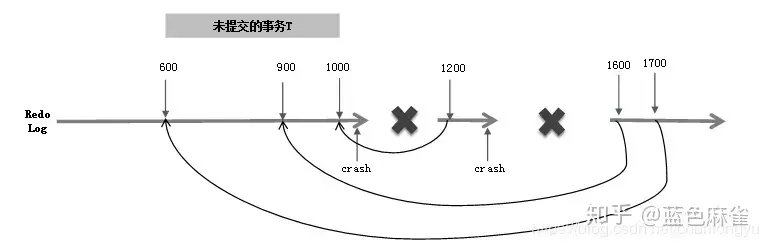
如图6-17所示,假设要回滚一个未提交的事务T,其有三条日志LSN分别为600、900、1000。第一次宕机重启,首先对LSN=1000进行回滚,生成对应的LSN=1200的日志,这条日志里会有一个字段叫作UndoNxtLSN,记录的是其对应的被回滚的日志的前一条日志,即UndoNxtLSN = 900。这样当再一次宕机重启时,遇到LSN=1200的CLR,首先会忽略这条日志;然后看到UndoNxtLSN = 900,会定位到LSN=900的日志,为其生成对应的CLR日志LSN=1600;然后继续回滚,LSN=1700的日志,回滚的是LSN=600。 这样,不管出现几次宕机,重启后最终都能保证回滚日志和之前的日志一一对应,不会出现“回滚嵌套”问题。
到此为止,已经对事务的A(原子性)和D(持久性)有了一个全面的理解,接下来将讨论I的实现。在此先对Redo Log做一个总结:
(1) 一个事务对应多条Redo Log,事务的Redo Log不是连续存储的。
(2) Redo Log不保证事务的原子性,而是保证了持久性。无论提交的,还是未提交事务的日志,都会进入Redo Log。从而使得Redo Log回放完毕,数据库就恢复到宕机之前的状态,称为Repeating History。
(3) 同时,把未提交的事务挑出来并回滚。回滚通过Checkpoint记录的“活跃事务表”+ 每个事务日志中的开始/结束标记 + Undo Log 来实现。
(4) Redo Log具有幂等性,通过每个Page里面的pageLSN实现。
(5) 无论是提交的、还是未提交的事务,其对应的Page数据都可能被刷到了磁盘中。未提交的事务对应的Page数据,在宕机重启后会回滚。
(6) 事务不存在“物理回滚”,所有的回滚操作都被转化成了Commit。
事务实现原理之2:Undo Log
1. Undo Log是否一定需要
说到Undo Log,很多人想到的只是“事务回滚”。“事务回滚”有四种场景: 场景1:人为回滚。事务执行到一半时发生异常,客户端调用回滚,通知数据库回滚,数据库回滚成功。 场景 2:宕机回滚。事务执行到一半时数据库宕机,重启,需要回滚。 场景 3:人为回滚 + 宕机回滚。客户端调用回滚,数据库开始回滚数据,回滚到一半时数据库宕机,重启,继续回滚。 场景 4:宕机回滚 + 宕机回滚。宕机重启,在回滚的过程中再次宕机。
对于这四种场景的解决方法,在上文的ARIES算法已经给出了答案,其中要用到Redo和Undo Log。这里扩展一下,除了ARIES算法,是否还有其他的方法可以做事务回滚?或者说,Undo Log是否一定需要?
回滚,就是取消已经执行的操作。无论从物理上取消,还是从逻辑上取消,只要能达到目的即可。假设Page数据都在内存里面,每个事务执行,都只在内存中修改数据,必须等到事务Commit之后写完Redo Log,再把Page数据刷盘。在这种策略下,不需要Undo Log也能实现数据回滚!因为在这种数据刷盘策略下,正好利用了“内存断电消失”的特性,磁盘上存储的全部是已经提交的数据,宕机重启,内存中还未完成的事务自然被一笔勾销了!在这种策略之下,未提交的事务不会进入Redo Log;未提交的事务,也不会刷盘,全都在内存里面。
把这个展开,就是Page数据刷盘的四种策略,如表6-10所示。下面对这四种策略进行详细分析:
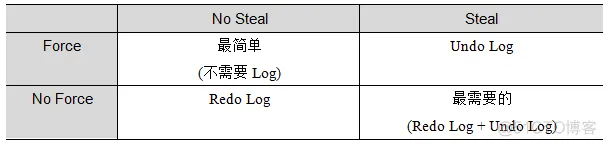
No Steal和Steal:指未提交的事务是否可以写入磁盘中?No Steal是未提交的事务不能写入磁盘,只能在内存中操作,等到事务提交完,再把数据一次性写入;Steal是指未提交的事务也能写入,如果事务需要回滚,再更改磁盘上的数据。
No Force和Force: 是指已经提交的事务是否必须写入磁盘?No Force是指已经提交的事务可以保留在内存里,暂时不用写入磁盘;Force是指已经提交的事务必须强制写入磁盘。
策略1:Force和No Steal。已经提交的事务必须强制写入磁盘,未提交的事务,只能保留在内存里,等事务提交后再写入磁盘,这种策略不需要Redo Log和Undo Log,仅靠数据本身就能实现原子性和持久性。但很显然不可行,未提交的事务不能写入磁盘,这还可以接受;已提交的事务必须强制写入磁盘,这需要多次I/O,性能会受影响,所以才有了RedoLog。
策略2:No Force和No Steal。已提交的事务可以不立即写入磁盘,未提交的事务只能保留在内存里。在这个策略下,只需要Redo Log即可,因为有“内存断电消失”这个天然特性。
策略3:Force/Steal。已提交的事务立即写入磁盘,未提交的事务也立即写入磁盘。这种只需要UndoLog回滚宕机时未提交的事务,不需要Redo Log。但和策略1一样,显然不可行,多次I/O的性能会受影响。
策略4:No Force/Steal。第4种策略是我们最想要的,也是InnoDB实现的策略。就是已经提交的事务可以不立即写入磁盘;未提交的事务可以立即写入磁盘,也可以延迟写入磁盘!再通俗一点,无论事务是否提交,既可以立即写入磁盘,也可以不写,写入磁盘时机任意,想什么时候写就什么时候写。
策略1和策略3因为性能问题不能接受,所以必须要有Redo Log。而策略4和策略2都可以接受,但策略4比策略2好的地方在于提高了I/O效率。因为事务没有提交,就开始写入磁盘,等到提交事务的时候,要写入磁盘的数据量会小,不然要把所有数据都累积到事务提交时再一次性写入磁盘。
也正是因为现代的数据库用的都是第4种,是最灵活的一种数据刷盘策略。在这种策略下,为了实现事务的原子性和持久性,才有了如此复杂的Redo Log和Undo Log机制,才有了上面的ARIES算法。
除了在宕机恢复时对未提交的事务进行回滚,Undo Log还有两个核心作用: (1)实现ACID中I(隔离性)。
(2)高并发。
2. Undo Log(MVCC)
在多线程编程中,读写的并发问题有三种策略

对比上面表格的三种并发策略可以知道,从上到下,并发度越来越高。而InnoDB用的就是CopyOnWrite思想,是在Undo Log里面实现的。每个事务修改记录之前,都会先把该记录拷贝一份出来,拷贝出来的这个备份存在Undo Log里。因为事务有唯一的编号ID,ID从小到大递增,每一次修改,就是一个版本,因此Undo Log维护了数据的从旧到新的每个版本,各个版本之间的记录通过链表串联。
也正因为有了MVCC这种特性,通常的select语句都是不加锁的,读取的全部是数据的历史版本,从而支撑高并发的查询。这种读,专业术语叫作“快照读”,与之相对应的是“当前读”。

3. Undo Log不是Log
了解Undo Log的功能后,进一步来看Undo Log的结构。其实Undo Log这个词有很大的迷惑性,它其实不是Log,而是数据。为什么这么说?
(1)Undo Log并不像Redo Log一样按照LSN的编号,从小到大依次执行append操作。Undo Log其实没有顺序,多个事务是并行地向Undo Log中随机写入的。
(2)一个事务一旦Commit之后,数据就“固化”了,固化之后不可能再回滚。这意味着Undo Log只在事务Commit过程中有用,一旦事务Commit了,就可以删掉UndoLog。具体来说:
对于insert记录,没有历史版本数据,因此insert的Undo Log只记录了该记录的主键ID,当事务提交之后,该Undo Log就可以删除了;
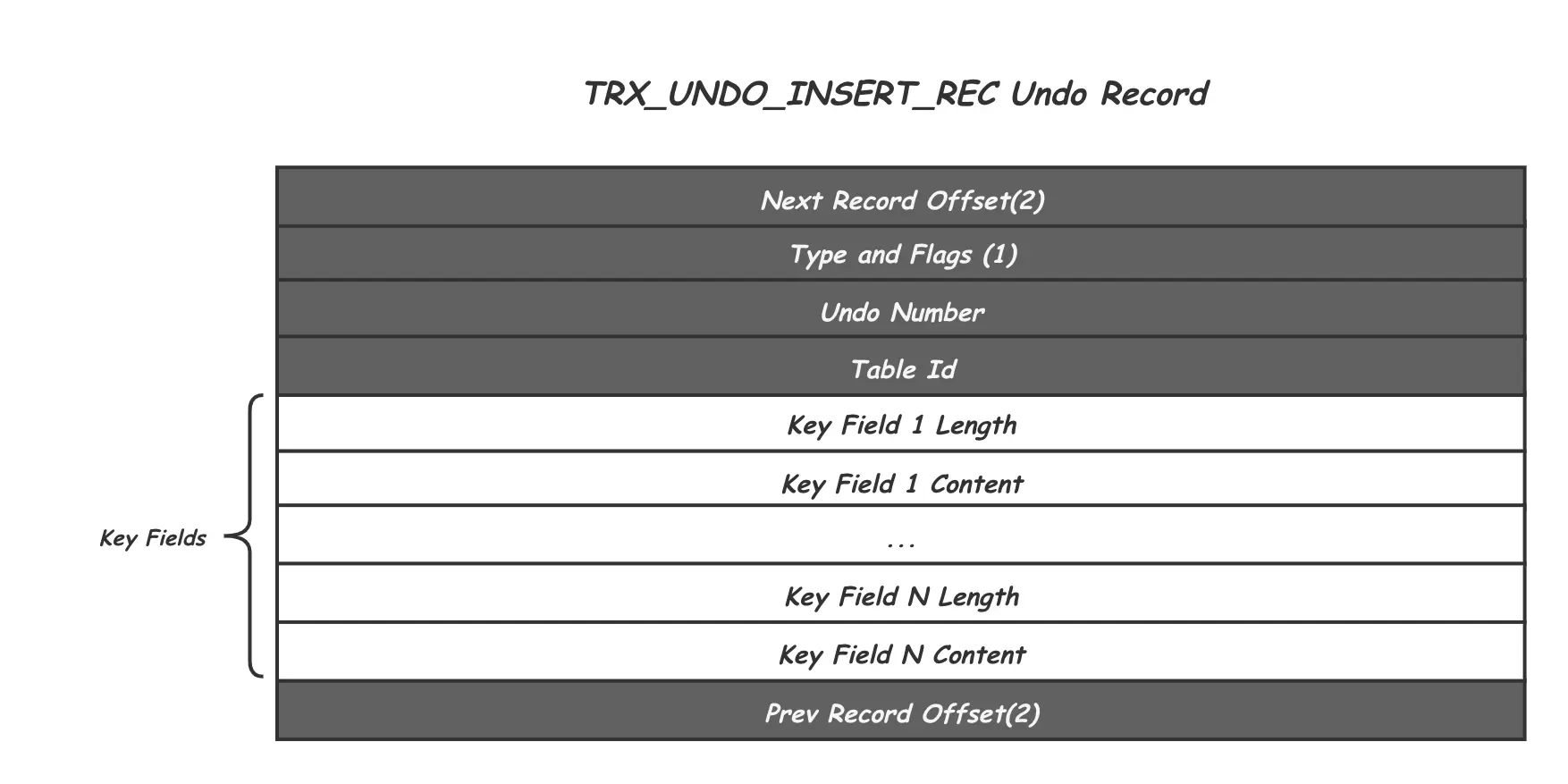
这种Undo Record在代码中对应的是TRX_UNDO_INSERT_REC类型。不同于Update类型的Undo Record,Insert Undo Record仅仅是为了可能的事务回滚准备的,并不在MVCC功能中承担作用。因此只需要记录对应Record的Key,供回滚时查找Record位置即可。
对于update/delete记录,因为MVCC的存在,其历史版本数据可能还被当前未提交的其他事务所引用,一旦未提交的事务提交了,其对应的Undo Log也就可以删除了。
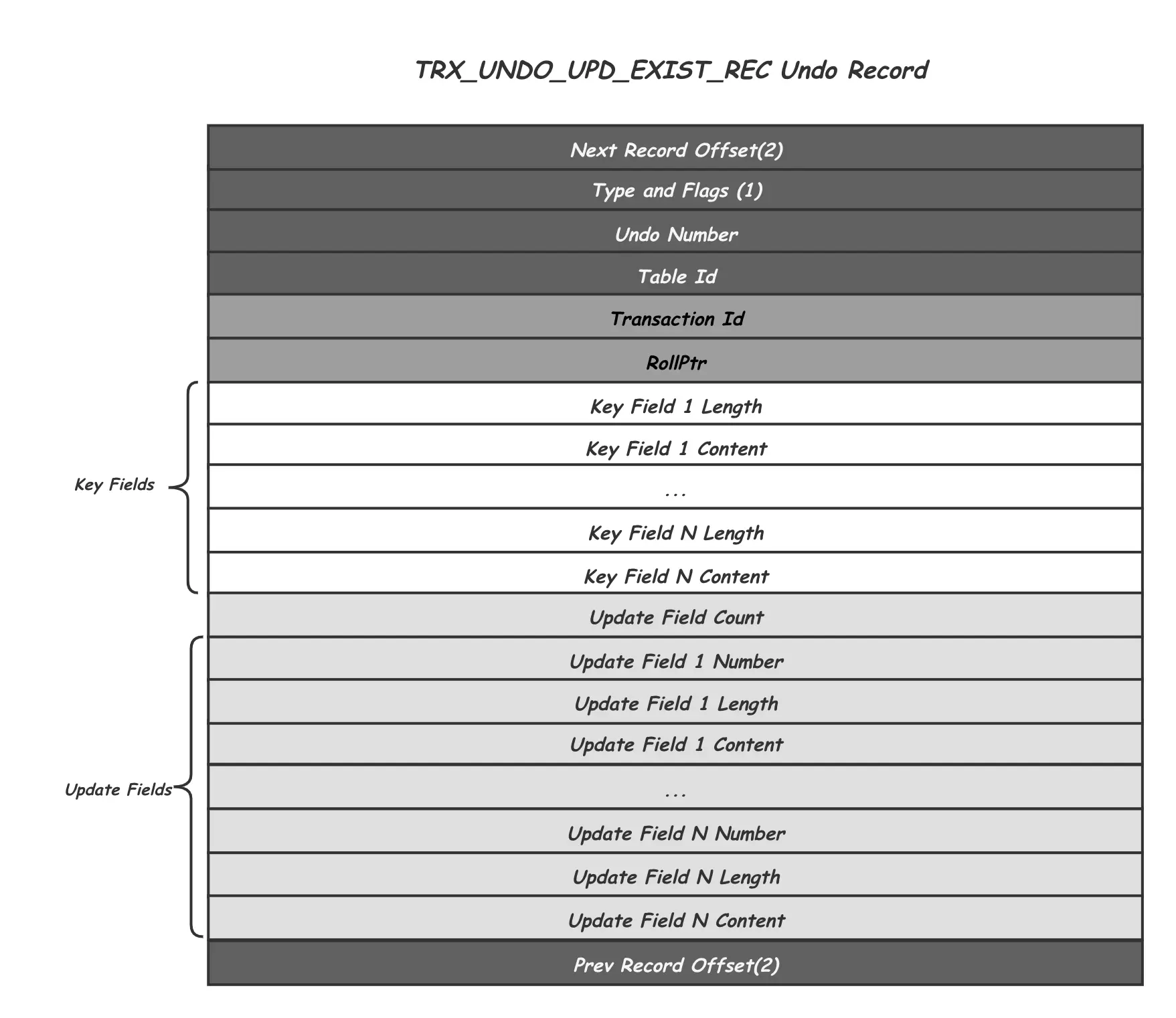
除了跟Insert Undo Record相同的头尾信息,以及主键Key Fileds之外,Update Undo Record增加了:
- Transaction Id记录了产生这个历史版本事务Id,用作后续MVCC中的版本可见性判断
- Rollptr指向的是该记录的上一个版本的位置,包括space number,page number和page内的offset。沿着Rollptr可以找到一个Record的所有历史版本。
- Update Fields中记录的就是当前这个Record版本相对于其之后的一次修改的Delta信息,包括所有被修改的Field的编号,长度和历史值。
所以,更应该把UndoLog叫作记录的“备份数据”,即在事务未提交之前的时间里的“备份数据”!提交事务后,没有其他事务引用历史版本了,就可以删除了。
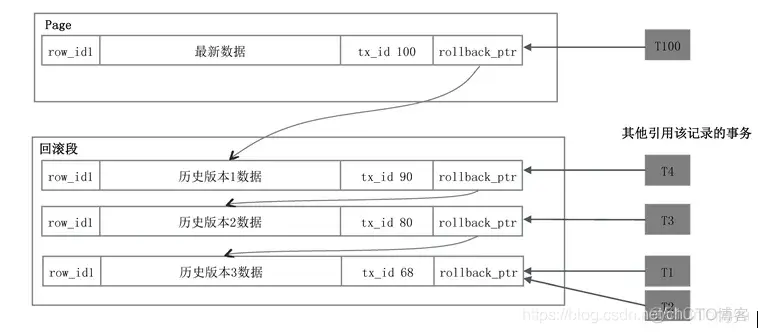
下面来看这个“备份数据”是怎么操作的。如图6-18所示,Page中的每条记录,除了自身的主键ID和数据外,还有两个隐藏字段:一个是修改该记录的事务ID,一个是rollback_ptr,用来串联所有的历史版本。假设该记录被tx_id为68、80、90、100的四个事务修改了四次,该数据就有四个版本,通过rollback_ptr从新到旧串联起来。
然后,三个历史版本分别被其他不同的事务读取。为什么会出现不同的事务读取到不同的版本呢?因为T1、T2最先,此时历史版本3是最新的,还没有历史版本1、2;之后该记录被修改,产生了历史版本2,然后出现了T3;之后该记录又被修改,产生了历史版本1,然后出现了T4。每个事务读取的都是这个事务执行时最新的历史版本。
这些历史版本什么时候可以删除呢?在T1、T2提交之后,历史版本3就可以删除了;在T3提交之后,历史版本2就可以删除了,依此类推。
4. Undo Log与Redo Log的关联
Undo Log本身也要写入磁盘,但一个事务修改多条记录,产生多条Undo Log,不可能同步写入磁盘,所以遇到了开篇讲Write-Ahead时的问题。如何解决Undo Log需要多次写入磁盘的效率问题呢? Redo Log记录的是对数据的修改,凡是对数据的修改,都必须记入Redo Log。可以把Undo Log也当作数据!在内存中记录Undo Log,异步地刷盘,宕机重启,用Redo Log恢复Undo Log。
拿一个事务来举例:
start transaction
update表1某行记录
delete表1某行记录
insert表2某行记录
commit
把Undo Log和Redo Log加进去,此事务类似下面伪代码所示:
start transaction
写Undo Log1: 备份该行数据(update)
update表1某行记录
写Redo Log1
Undo Log2:备份该行数据(insert)
delete 表1某行记录
写Redo Log2
Undo Log3:该行的主键ID(delete)
insert表2某行记录
写Redo Log3
commit
在这里,所有Undo Log和Redo Log的写入都可以只在内存中进行,只要保证Commit之后Redo Log落盘即可,Undo Log可以一直保留在内存里,之后异步刷盘。
总结:事务的实现
前面讲的重做日志,回滚日志以及锁技术就是实现事务的基础。
- 事务的原子性是通过 undo log 来实现的
- 事务的持久性是通过 redo log 来实现的
- 事务的隔离性是通过 (读写锁+MVCC)来实现的
- 而事务的终极大 boss 一致性是通过原子性,持久性,隔离性来实现的!!!
文档信息
- 本文作者:L1Chenxv
- 本文链接:https://l1chenxv.github.io//2023/09/14/transaction-implementation/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)